
Data quality is foundational to customer confidence.
At SecurityScorecard, our Scoring platform processes data for thousands of companies daily. That scale requires more than strong engineering discipline. It requires clear validation patterns, consistent checks, and observable results across every critical stage of the pipeline.
This post shares how our data engineering team uses Great Expectations, DataHub, and Apache Airflow to build repeatable data quality checks into scoring workflows. The goal is simple: make validation consistent, visible, and easy to extend as our systems scale.
For teams building complex data pipelines, the key lesson is this: manual checks can work early, but long-term consistency requires standardization. Great Expectations gives teams a common way to define validations. DataHub gives teams a shared view of results. Together, they help make data quality measurable across projects.
The Problem: Missing Visibility In The Data Pipeline
Our workflow processes data for thousands of companies daily. It flows through a complex Airflow pipeline spanning multiple stages: from ingesting raw input files, through computation, to syncing results across several databases before they reach customer-facing APIs.
Our codebase had good coverage, comprehensive unit and integration tests. We wanted to expand that deeper into the data layer. That includes:
- Improving validation of input data before compute-heavy jobs
- Improving checks that outputs are reasonable
- Improving verification that database syncs complete as expected
- Improving monitoring for business rule conditions
- Building a centralized view of data quality status
The target state was clear: validation should run automatically at every meaningful stage. What we really wanted was something like:
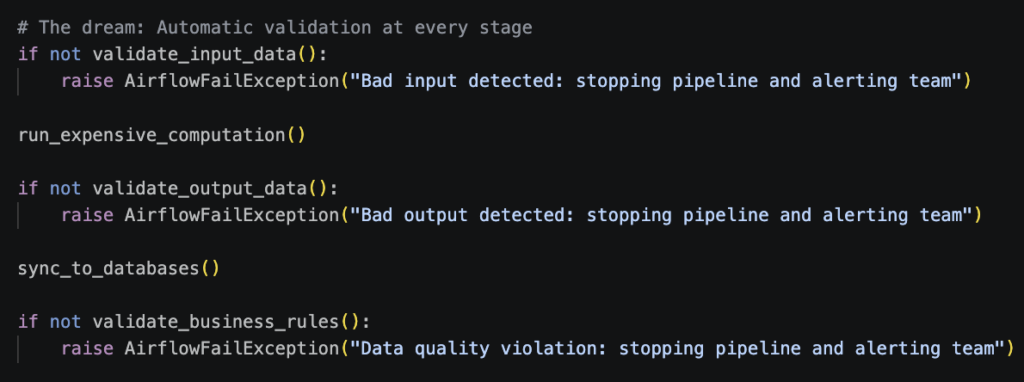
This pattern lets teams catch unexpected changes early, standardize how checks run, and make results visible.
Enter Great Expectations and Datahub
After researching solutions, we decided on an approach using:
- Great Expectations (GX) – For schema validation and standardized data quality checks
- DataHub – For centralized data quality monitoring and observability
- Apache Airflow – For orchestration and pipeline control (already our workflow engine)
The key insight was that implementing checks manually is easier initially. Maintaining those checks long-term requires consistency across repositories. Great Expectations standardizes how you write validations and how you format results, making it easier to integrate with observability platforms like DataHub while keeping things consistent across projects.
The Solution: Multi-Layer Validation
We implemented validation at multiple critical stages, creating a defense-in-depth approach:
Stage 1: Input Validation (Before We Spend Money)
Before kicking off expensive computation jobs, we validate that input data looks reasonable. We use Great Expectations to load the input data into a validator and run a set of expectations against it. These checks include row count comparisons, null checks on key columns, and schema validation:
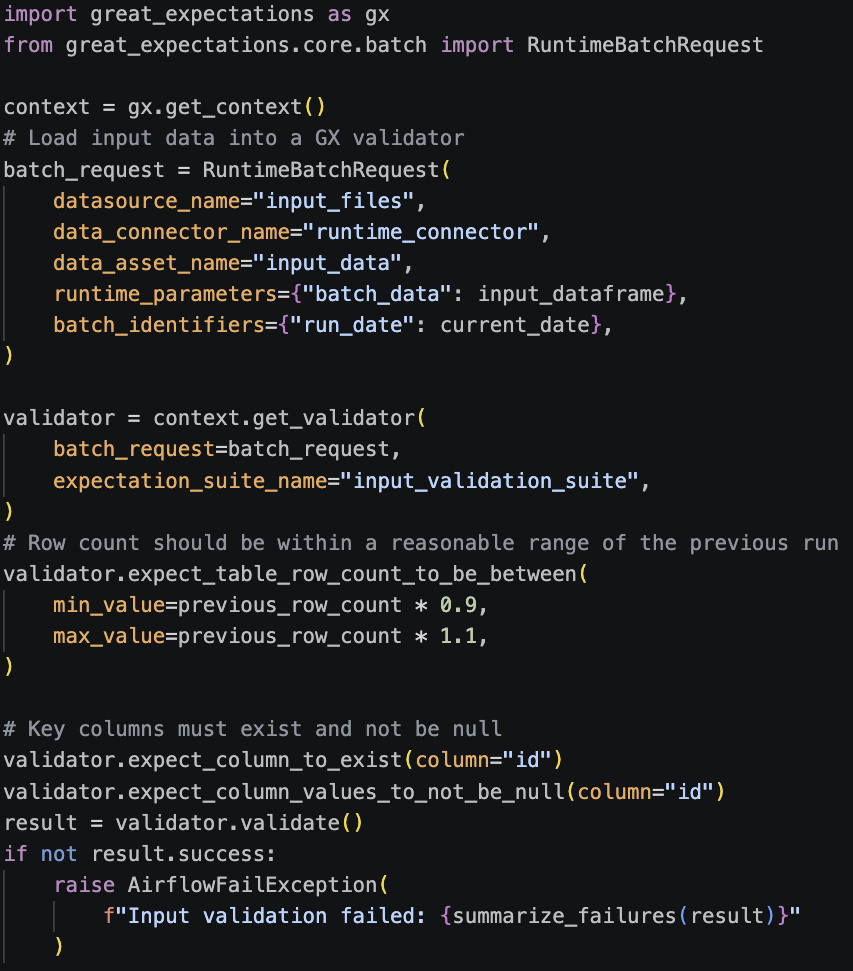
Why this matters: row count checks help teams detect unexpected upstream changes early. That protects compute efficiency and keeps validation close to the source.
Stage 2: Output Validation (After Computation)
After computation completes, we run a similar set of GX checks on the output data before syncing it anywhere. We validate row counts, check for nulls in required fields, and verify that values fall within expected ranges:
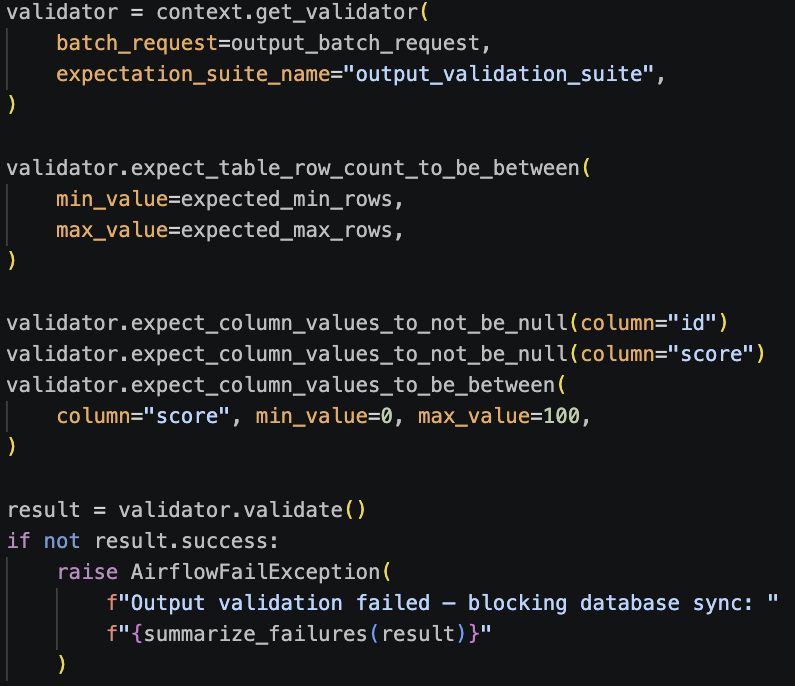
If outputs fall outside expected parameters, the pipeline pauses before syncing downstream. That keeps validation decisions close to the workflow.
Stage 3: Database Validation (Great Expectations + Custom SQL)
Once data lands in our databases, we run two types of checks.
Schema validation with Great Expectations: connecting GX directly to the database via SQLAlchemy and running expectations against the live tables:
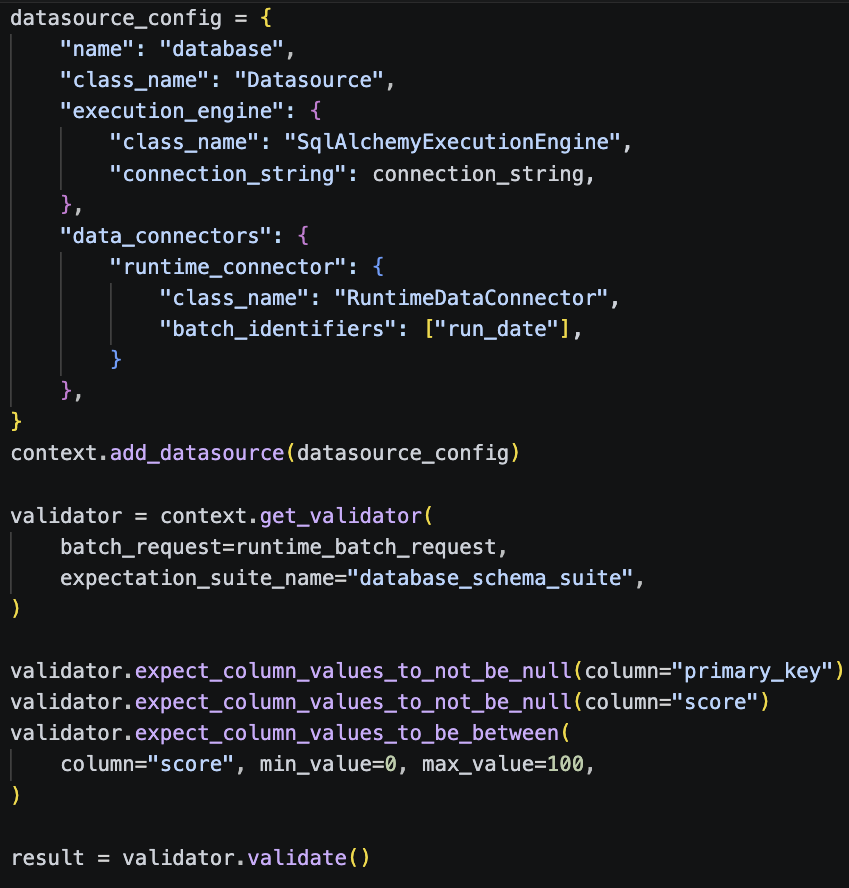
Business rule validation with direct SQL: this is where we learned an important lesson. We initially tried using Great Expectations for all of our business rule checks. GX was fetching millions of rows into memory and validating each one in Python. What should have taken seconds was taking minutes. Refactoring to use database-side queries made rules more interactive, improved runtime performance and relieved pressure on the airflow instance.
We refactored the business rules to use database-side SQL queries instead:
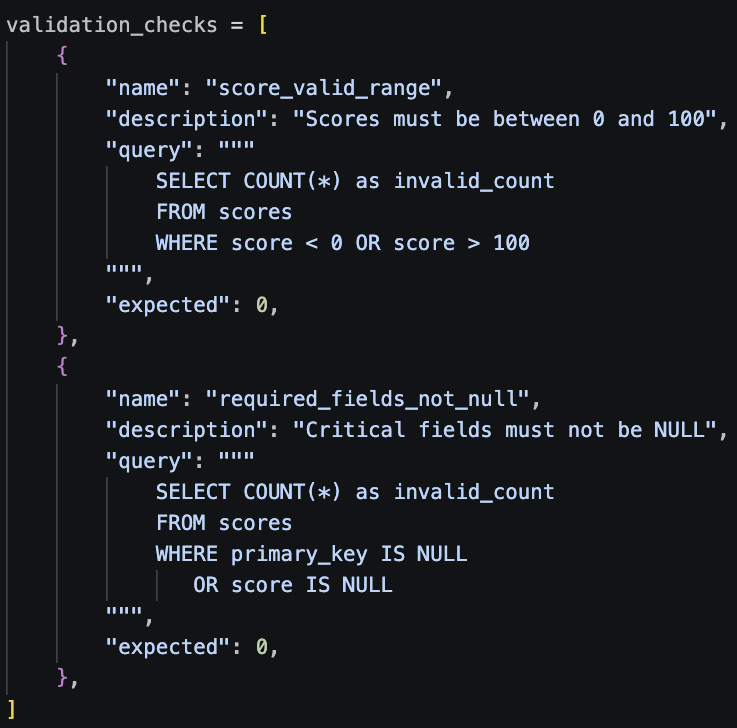
for check in validation_checks:
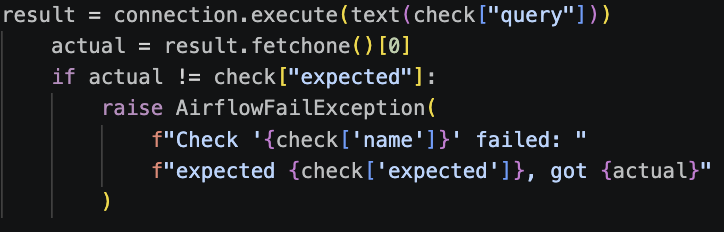
The result was faster validation, with checks going from minutes to seconds. The takeaway: use the right tool for the job. GX is excellent for schema validation and provides standardized results you can forward to an observability platform. For business rules on large tables, let the database do the heavy lifting.
Stage 4: Final Gate Validation
Our last database, the one closest to customer-facing APIs, gets the most comprehensive validation. We combine GX schema checks with an extensive set of SQL-based business rule checks. If a validation check falls outside policy at this stage, the pipeline pauses and alerts the on-call team. This creates a clear final control point before customer-facing systems.
Observability: DataHub Integration
Validation checks become more useful when teams can see trends, results, and context in one place.
Validation checks aren’t very useful if you can’t see what’s happening. All of our validation results are automatically published to DataHub as assertions, giving us:
- Pass/fail status tracked over time
- Expected vs actual values for every check
- Execution timestamps and run metadata
- Human-readable descriptions
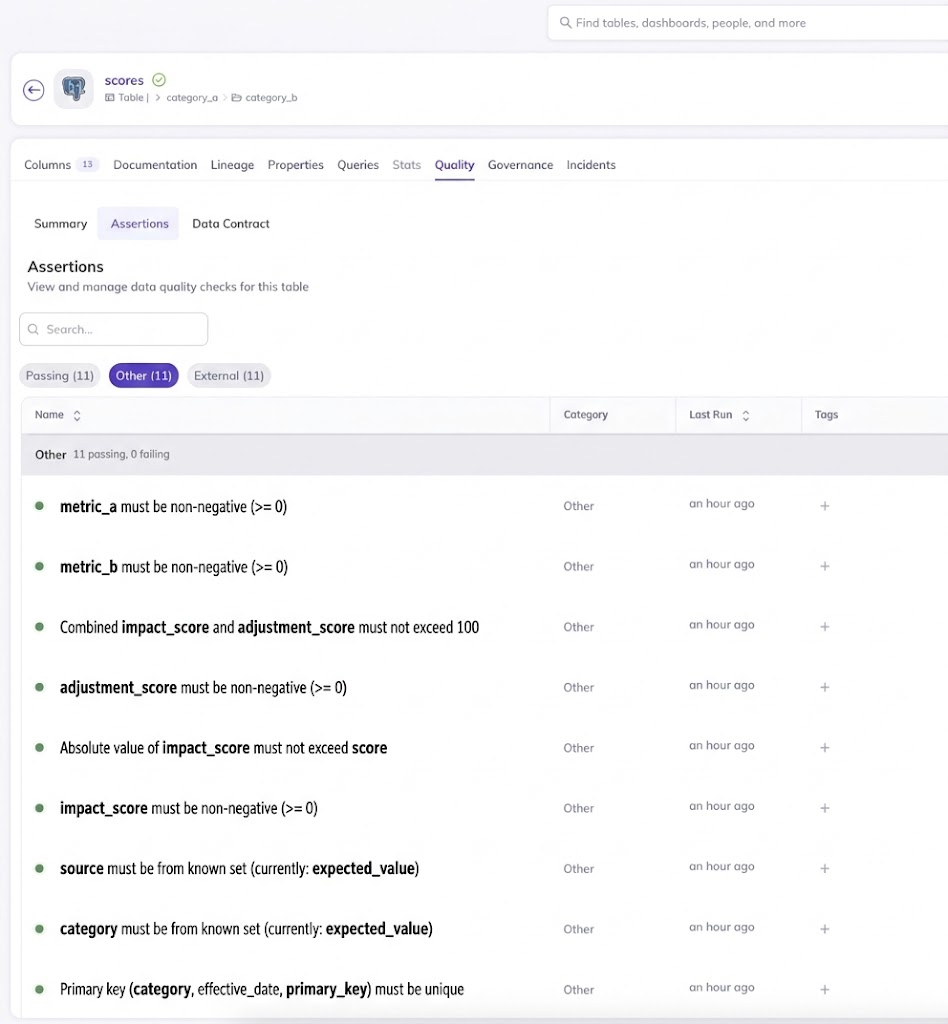
This gives us a single pane of glass for data quality across all of our systems. When a validation check needs attention, teams can see what changed, when it changed, and which dataset is affected.
How This Has Helped Us
Since rolling out this system, we have strengthened how teams validate, monitor, and evolve scoring data workflows.
Earlier signal detection: Validation checks help identify unexpected changes close to their source. Row count changes, file size anomalies, and schema shifts become visible sooner in the process.
Faster response: Teams now get specific validation messages, exact counts, DataHub context, and automated pipeline controls. This reduces investigation time and clarifies ownership.
Developer confidence: Engineers can change pipeline logic with a consistent validation layer in place. Adding new checks is straightforward. Teams can include data checks during development, not after release.
Lessons Learned
Use the right tool for the job: We use Great Expectations for schema validation because it gives us standardization and easy DataHub integration. We use direct SQL for business rules on large tables because performance matters. We use simple file size comparisons for input/output checks because sometimes the simplest approach is the best one. Don’t force every check through the same framework.
Performance matters: Our initial approach of fetching millions of rows into Python for validation was elegant but slow. When dealing with large datasets, push the work to the database. Profile before you commit to an approach.
Validate early, alert clearly: If validation doesn’t pass, we stop the pipeline immediately, send detailed alerts to on-call, emit the information to DataHub with context, and include actual vs expected values in the message. Every validation result should produce useful context for the team.
Make it easy to add checks: If adding a new validation check requires modifying five files and understanding complex abstractions, people won’t add them. We designed our system so that adding a check is as simple as adding an entry to a list.
Observability makes validation scalable: DataHub integration was critical for understanding data quality trends over time, debugging failures quickly, and demonstrating data quality posture to stakeholders.
Wrapping Up
Data quality validation is core engineering work. It builds confidence in complex systems and helps teams scale responsibly.
By adding validation across multiple pipeline stages, choosing the right tool for each check, and publishing results into DataHub, we made data quality easier to measure and improve.
For teams running complex data pipelines, start with the highest-value checks. Standardize how validations run. Make results visible. Then keep extending the system as your workflows grow.


